In March I am going to teach the Progressive Enhancement course of the Web minor at university for the third time. I decided to expand the reading list for this course, and here I present the version I’m going to use in 2021.
Notes about HTML, CSS or JavaScript coding techniques.
| Contest | Memory leaks | Touch events | Viewports | XMLHTTP | position fixed | rafp |
In March I am going to teach the Progressive Enhancement course of the Web minor at university for the third time. I decided to expand the reading list for this course, and here I present the version I’m going to use in 2021.
In March I am going to teach the Progressive Enhancement course of the Web minor at university for the third time. I decided to expand the reading list for this course, and here I presented draft 1 and asked for feedback.
Meanwhile the reading list is done and I removed this draft. Also, I have a question about progressive enhancement and accessibility that I wasn't able to solve.
The story goes as follows: Once upon a time there was a meta viewport property called user-scalable=no that suppressed pinch zoom on the page it was on. As a result users could not zoom in, even if they needed to. This was obviously a bad idea, and therefore browsers stopped supporting it.
At least, I thought that was the story. Turns out it isn’t.
When I announced I was going to write something for JavaScript developers who don't understand CSS, plenty of people (including Jeremy) said that the Cascading & Inheritance chapter would be crucial, since so many JS developers didn’t seem to understand it.
At first I agreed, but later I started to harbour some doubts, which is the reason I’m writing this piece.
18 December 2017
In this third part of a three-part article we will continue our study of native form validation in browsers. Part 1 discussed general UI considerations and CSS. Part 2 studied a few HTML properties and the JavaScript API.
In this part we will consider the native error messages and offer general recommendations to come to actually usable native form validation.
((This article was originally published on Samsung Internet’s Medium channel. Since I do not believe Medium will survive in the long run I re-publish it here.)
In this second part of a three-part article we will continue our study of native form validation in browsers. Part 1 discussed general UI considerations and CSS. Part 3 will discuss the native error messages and offer general recommendations to come to actually usable native form validation.
In this part we’re going to take a look at a few HTML features and the JavaScript API.
((This article was originally published on Samsung Internet’s Medium channel. Since I do not believe Medium will survive in the long run I re-publish it here.)
After doing exhaustive research into modern CSS and JavaScript form validation, I present my conclusions in this series of articles. It will discuss HTML validation messages, the CSS :invalid and :valid pseudo-classes, and the Constraint Validation API that is supposed to make form validation easier but doesn’t really.
In this article we will attempt to validate a form in a user-friendly fashion entirely by using existing native HTML, CSS, and JavaScript features, writing a few very light custom scripts to pull some supposedly-easy strings in the Constraint Validation API.
((This article was originally published on Samsung Internet’s Medium channel. Since I do not believe Medium will survive in the long run I re-publish it here.)
My current project requires me to use Mutation Observers, and I couldn’t resist the temptation to do a little fundamental research. Overall they work fine, but there is one tricky bit when it comes to text changes. Also, I found two Edge bugs.
My current client asked me to keep track of DOM nodes that appear onmouseover — and my script should work in pretty much any site. So we have add some information to DOM nodes that appear onmouseover, which will allow a later script to figure out that there was a mouseover involved. That’s obviously a job for Mutation Observers.
Here’s Microsoft’s documentation for Mutation Observers, which I find clearer than the MDN page.
Today I spent about an hour in writing a few very simple Intersection Observer tests, two hours in running them in a few browsers, and now an hour in writing down the results.
I’ve only just started my research, but can already draw a few odd conclusions, which make me fear Intersection Observers are not yet ready to be deployed on a large scale, particularly on mobile.
During the introduction of the iPhone X a hilarious gif made the Twitter rounds, showing a list scrolling past the new notch.
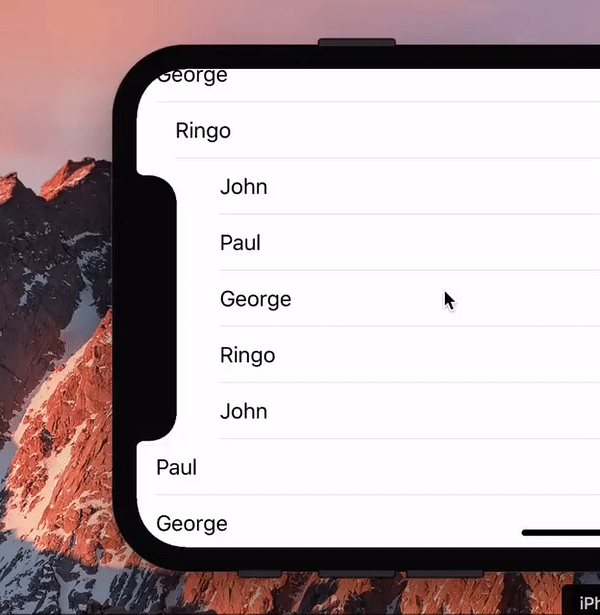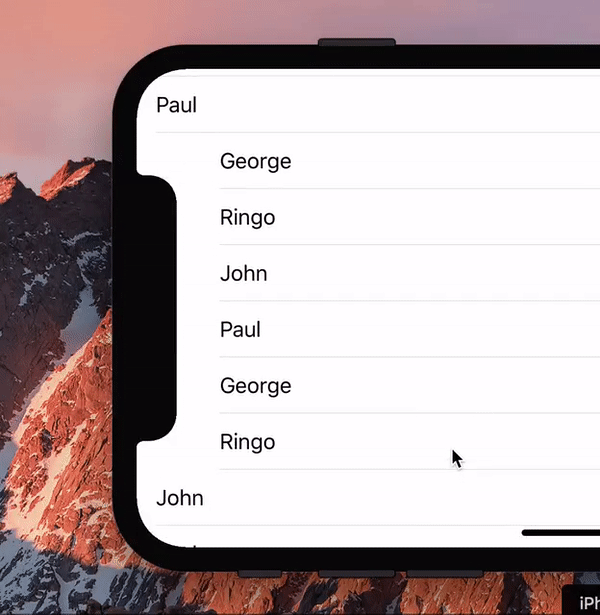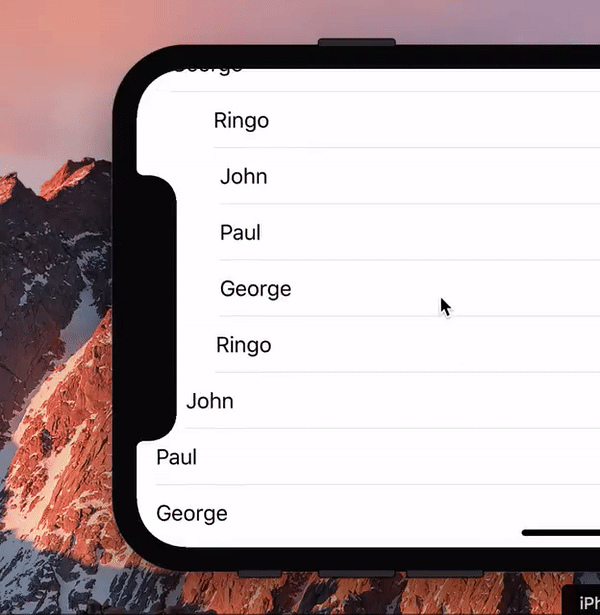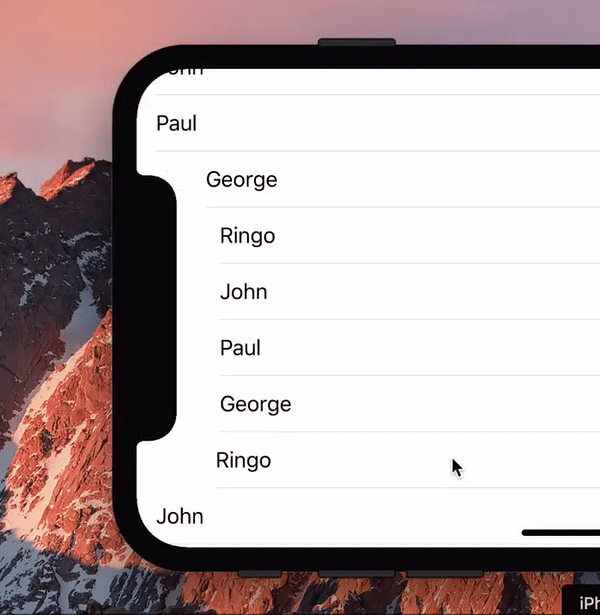
I asked the question any web developer would ask: “Hey, is this even possible with web technology?” Turns out it is.
(We should probably ask: “Hey, is this a useful effect, even if it’s possible?” But that’s a boring question, the answer being Probably Not.)
So for laughs I wrote a proof of concept (you need to load that into the iPhone X simulator). Turns out that this little exercise is quite useful for wrapping your head around the visual viewport and zooming. Also, the script turned out to be quite simple.
A few weeks back the most exciting viewport news of the past few years broke: Chrome 61 supports a new visual viewport API. Although this new API is an excellent idea, and even includes a zoom event in disguise, the Chrome team decided that its existence warrants breaking old and trusty properties.
I disagree with that course of action, particularly because a better course is readily available: create a new layout viewport API similar to the visual one. Details below.
All mobile browsers have two viewports. The layout viewport constrains your CSS — width: 100% means 100% of the layout viewport — while the visual viewport describes the area of the page the user is currently seeing. This visualisation of the two viewports might be useful as a reminder.
Today’s article studies what happens when these viewports change size. It also studies the resize event.
Some viewport changes are welcomed, such as the visual viewport resize after an orientation change or a zoom action. Others are esoteric, such as rewriting the meta viewport tag. Still others are seen as an annoyance, notably the appearance and disappearance of browser toolbars and the software keyboard.
(This article was originally published on Samsung Internet’s Medium channel. Since I do not believe Medium will survive in the long run I re-publish it here.)
Three weeks ago I redid my mobile viewports tests for the umpteenth time, and today I give you my overview. There is some progress to report, but also a lot of changes.
Highlights:
screen.width/height now gives the dimensions of the ideal layout viewport in nearly all mobile browsers.getBoundingClientRect() is relative to the visual viewport in most browsers, but relative to the layout viewport in Chromium 50+ and Edge.Touch/Click.clientX/Y has the same problem: it is relative to the visual viewport in most browsers, but relative to the layout viewport in Chromium 45+ and Edge.Touch/Click.screenX/Y is still chaotic. Don’t use.There we go again. The desktop browsers, over my strenuous objections, decided to treat DPR (device pixel ratio) as a variable instead of a constant when the user uses page zooming instead of pinch zooming.
The advantages or disadvantages of this decision are not what currently interests me, though I continue to have my doubts.
What we’re going to study today is the practical application of that idea: if DPR is a variable, responsive images should respond to page zoom. Do they? Safari doesn’t, Firefox does but has weird rounding, while Chrome/Opera and Edge each have their own bug but do normal rounding.
29 March 2016
I would like to propose a way of measuring the current performance of websites in real-world browsers with requestAnimationFrame. The really weird thing is that almost no one seems to have thought of this before.
The approach is very simple and a few tests show it appears to be worthwhile. I mean, it would be seriously cool if we find a reliable method to progressively enhance a site on-the-fly by turning off features if it turns out this specific browser is plagued by bad performance.
The basic idea is very simple: repeat requestAnimationFrame calls during one second, count how many times it’s called, and use the result to draw conclusions on the current performance of your website in your user’s browser. If the FPS (frames per second) rate starts to go down the browser is having more problems with executing your CSS or JavaScript, and it might be advisable to turn off, say, animations, or that one complicated DOM script that rewrites a table all the time.
Instead of the work I was supposed to do I spent about a day and a half on the alpha version of a viewports visualisation app that, oh irony of ironies, only works on desktop browsers because of the necessary space.
It’s already been very useful to me, since figuring out how the viewports actually work is necessary for full understanding. I hope it does the same for you.
It also contains an example of absolute, fixed, and device-fixed position so that you understand the difference.
The app is by no means ready; there’s a ton of features I’d like to add. Still, for now I’ve run out of time, and as long as it’s impossible to actually make money with such apps I’m not sure how much time I’m willing to spend on it.
11 February 2016
Last week I found out that as of Chrome 48 window. no longer exposes the dimensions of the visual viewport. Instead, it now exposes the dimensions of the layout viewport, and is thus a copy of document..
I’m not happy with this change. So it’s time for me to don my ceremonial robes as Guardian of the Viewports and ask the Chrome team to revert this change and restore the visual viewport to its rightful place.
There are three reasons why I think Chrome is making a mistake here:
A quick note on styling placeholder texts. Although it’s very easy, it turns out that both MDN and the usual go-to CSS Tricks article leave out one important bit of data: when setting the color you should add opacity: 1 for Firefox.
I’m currently working on my first real paid coding project in ages: PvdApp, a project of a friend of mine. (He paid for this research, so he deserves a link.)
Among other things, this project requires me to style and script sliders. There are several interesting points I would like to bring to your attention, such as a few underreported IE problems, the solution to Android WebKit’s appearance bug, and the proper use of the input and change events. And a quick syntax overview is always useful.
Back in April I lamented numerous problems and vaguenesses in the current W3C Device Adaptation spec. One of the spec’s editors, Florian Rivoal, contacted me, agreed that the spec had some problems, and explained some of its less clear features to me. In return, I explained some features I think should be added to the spec.
Within about ten mails we had agreed on the features that a future version of the spec should contain. This article summarises our conclusions, and adds a few questions a future version of the spec should answer.
Also, this article serves as a quick overview of where the viewports stand today. Everything described below works in almost all browsers right now, with the exception of the @viewport syntax. So this is useful reading for every web developer.
Finally, there’s one question that must be answered: If you use (x-based) responsive images on a desktop site, and the user zooms in, should you load the higher-DPR images? The answer is important for defining desktop DPR and screen.width/ height.
After last week’s rant about, among other things, the W3C Device Adaptation spec, one of the spec’s authors asked me to clarify my critique. Fair enough. Here’s my take on the current specification.
My critique of Device Adaptation consists of three main themes:
@viewport syntax, it does not treat the relevant JavaScript properties such as window.innerWidth and devicePixelRatio. That latter, especially, could do with some specification.15 April 2015
Today I rant about undocumented Chrome features and unreadable W3C specs. There’s too much of both nowadays, and I’m getting VERY tired of both. Google and W3C should clean up their act.
A friend of mine bought a fairly cheap (so probably not-too-new) Samsung smart TV to watch football, then promptly went on holiday with his family and asked me to feed the cat. In return I demanded the remote for the TV, and the manual (which turned out to be useless). So here’s my report of my first ever smart TV browser test.
By default, if you tap on a touchscreen it takes about 300ms before a click event fires. It’s possible to remove this delay, but it’s complicated. I investigated it.
25 March 2014
Permalink | in Conferences, Viewports
Desktop browsers have only one viewport: the browser window. In contrast, mobile browsers have three: layout, visual, and ideal. Why is that? What does it mean for the meta viewport, media queries, and all the rest? Why does responsive design work? (Not how. Why.) And how are the desktop browsers reacting to this series of new concepts coming from the mobile side?
Returning false, or calling preventDefault(), in an event handler is supposed to prevent the default action of the event. So if a user clicks a link the link is not followed, if the user scrolls nothing actually happens, etc. Does this work everywhere for the touch events? My latest research gives the details.
From Friday until today I spent far too much time reverse-engineering iOS behaviour I was already supposed to be aware of. However, I also found a twist that hasn’t been documented so far — I think.
The behaviour I should already have known about was that during the touch event cascade, Safari iOS stops firing events when a DOM change takes place. The twist is that only DOM methods such as appendChild() count — but innerHTML does not.
Many thanks to Patrick Lauke for helping me out here and putting me on the right track.
It’s that time again when I worry about the bubbling of mouse events on Safari iOS. Three years ago I did some research and a follow-up, and I found that the click event refused to bubble up to the body or higher in Safari iOS, unless some specific criteria were met. Today I repeated that research, and found the situation has changed.
Just now I published the latest touch action tests. There are no nasty surprises, although IE remains idiosyncratic.
The most common touch action is the single tap. When that action occurs, browsers fire off a whole slew of events, mostly in order to remain backward compatible with older sites that only use mouse events. Although there are quite a few deviations from the “standard” order of these events, they don’t matter much. The average script won’t break because the mouseover event fires before the touchstart event. Still, I documented all deviations. Who knows when this will come in handy?
I also studied the double tap, pinch-zoom, and scroll actions and found that browsers generally fire those events you would expect. The contextmenu event, which could serve as a useful proxy for a touchhold actions, is badly supported.
I also updated the mobile events page with the new information gleaned from these tests.
Enjoy.
16 January 2014
Just some random notes from the trenches in order to show everyone that, despite appearances, the viewport is not simple or easy to understand.
A browser vendor asked me to study the following problem:
I redid the CSS2 tests in the mobile browsers; that is, the declarations that were never added to a CSS3 module. Since position: fixed is part of my CSS2 tests, it’s time for an update.
Just a pointer: I created a quick and dirty overview table of where the mobile viewports and related concepts stand right now.
May be useful if you’re new to this sort of stuff.
Well, some discussion has certainly started about my first and second desktop media query bug reports. A redux is useful.
First, some good news. The way the resolution media query is currently behaving in Chrome is a bug, and it’s in the process of being fixed. That takes a load off my shoulders; for a moment I was afraid it was designed this way. But it’s not.
This does not say anything about the underlying issues I have with redefining DPR, though. Apart from the technical issues, there’s a cultural issue, if you wish. The discussions clarified my thinking and I can now describe it.
I recently tested media queries in both mobile and desktop browsers, and found that the desktop browsers are making several serious mistakes in their implementation that threaten to pull apart the mobile and desktop worlds.
I feel the desktop browsers should defer to their mobile cousins in viewport matters, since mobile is the more complicated use case and a de-facto standard is emerging. Their recent actions threaten this process. The previous article treated rounding errors and problems with the width media query. This article will treat the very complicated DPR problem.
Briefly, desktop browsers recently changed the meaning of device-pixel-ratio to zoom level. I feel that this information should be moved to a new JavaScript property, media query, and JavaScript event, because squeezing it in with the existing mobile-based device-pixel-ratio properties and media queries has all kinds of odd consequences.
I recently tested media queries in both mobile and desktop browsers, and found that the desktop browsers are making several serious mistakes in their implementation that threaten to pull apart the mobile and desktop worlds.
I feel that desktop browser makers have focused on desktop use cases too narrowly and failed to see that these changes introduce deliberate incompatibilities between desktop browsers and mobile browsers. It’s web developers who have to solve this mess, and it’s likely they can only do so by using browser detects.
Yesterday I tested screen.width/height and related properties in the mobile browsers. The conclusion is that screen.width/height is completely unreliable.
There are two competing definitions of what screen.width/height actually means. In addition, a lot of browsers either ignore both definitions or have bugs in their implementation.
Thus, when analytics packages proudly present screen resolution stats, they don’t know what they’re talking about and you’d do best to ignore them. The package has no clue what kind of measurements it gets, but pastes the result into the database anyway and pretends it means something profound.
6 November 2013
I published my research on the orientationchange and resize events on mobile. If you’re expecting plenty of browser incompatibility fun you won’t be disappointed.
5 November 2013
Last week Luke Wroblewski published an important article in which he said that web developers practising responsive design rely too much on a device’s screen size to determine which device it is.
Here’s an update to my recent viewport research about the height directive and the @viewport alternative syntax.
Summary: height doesn’t work. @viewport works only on Opera Presto, with the proper vendor prefix, which basically amounts to “doesn’t work.”
Just now I released my preliminary meta viewport research that studies the various permutations of the <meta name="viewport"> tag.
It’s preliminary because I tested it in only eight browsers instead of the customary 40, I did not yet test the @viewport CSS rule, and I’ll probably need some extra tests to cover edge cases. Still, I now have a pretty good overview of where we stand with regard to the meta viewport.
Turns out Tuesday’s post was not so much wrong as incomplete. I was tripped up by what’s probably the most complicated feature (or bug) in the meta viewport space, and my conclusions weren’t entirely correct.
Also see this post for the full research.
15 October 2013
One common problem on iOS is that, when you use a meta viewport tag with width=device-width, the page doesn’t react to an orientation change. On the iPhone the page becomes 320px wide and on the iPad 768px, regardless of whether you’re in portrait or in landscape mode. Sometimes this is annoying.
Today I found a solution: use initial-scale=1 instead of . Although I’m not the first one to discover this (see, for instance, this article in French) it doesn’t seem that this solution is well-known.width=device-width
See this post for an update, and this post for the full research.
Yesterday I found that proper hyphenation of text is now supported by Firefox, IE10, and Safari. So I added it to my main style sheet and it should work in these browsers across my site. I also advise you to add it to your sites straight away.
20 October 2012
Permalink
| in Coding techniques
6 comments
(closed)
During my media query test I found out that min-resolution: 0[unit] does not work in any browser for any unit. I find this weird.
OK, there’s a budding consensus on how position: fixed should work on mobile. Android WebKit and Chrome both do it, and in iOS6 Safari has dropped the weird iOS5 stuff and moved to a sensible solution.
Instead of explaining it in words, here’s a video. HTC One X, Android 4.0.3, Android WebKit default browser. Test page.
11 July 2012
Last week I got annoyed at the large differences in syntax for vendor-prefixed device-pixel-ratio media queries. I said, half in desperation and half as a threat, that it might be better to have only the WebKit rendering engine and ditch the rest.
Meanwhile I’ve had some time to think about it, and I find that I still support the idea of multiple rendering engines. Competition is still good, just as it was ten years ago.
HOWEVER. There’s an important exception.
It occurs to me that my recent post about devicePixelRatio was a bit cryptic and short. So I will givde some extra examples in this post. Also, I did some additional research that takes screen.width into account.
Remember the definition:
devicePixelRatio is the ratio between physical pixels and device-independent pixels (dips) on the device.
devicePixelRatio = physical pixels / dips
I did some research around the window.devicePixelRatio property that all WebKit browsers, as well as Opera, support, and for once the news is good. This property’s definition makes sense, and it is implemented almost universally.
Yesterday I finally researched window.outerWidth/Height in the mobile browsers, and here are my conclusions.
A few months back James Pearce published research that shows that the use of window.outerWidth on iOS devices allows you to read out the true orientation; something that screen.width does not.
Yesterday I came to the conclusion that this is far and away the most interesting use window.outerWidth has, and that James also missed a completely idiotic effect that Apple provides. The rest of the browsers are much more boring in their implementation.
Now that iOS, Android, and BlackBerry all have a new implementation of position: fixed let’s see what changed since the last time we looked.
Because it’s fairly hard to describe what mobile and tablet browsers do to position: fixed I decided to make four short videos, both to help you understand the issues better, and to practice a bit with shooting videos of mobile browsers.
Last week I did some research on the resize event on mobile and tablet browsers. Executive summary: it’s a mess. And the best browser, surprisingly, is Samsung’s Dolfin.
My conclusions are, summarised:
Yesterday James Pearce published important research into the nature and measuring of the mobile browser viewports. One finding is so important that I write this quick entry even though I haven’t yet fully researched it.
On a hint from Vasilis I did some quick research into dynamically changing the meta viewport tag. Turns out that this works in nearly all browsers that support it in the first place, with the exception of Firefox. This entry gives the details and explains why you should care. See also the inevitable compatibility table.
W3C unveils the Touch Events Specification. It’s a rough draft, I guess — it doesn’t even have an official URL on www.w3.org yet. But I like it a lot.
7 December 2010
Permalink
| in Viewports, position fixed
32 comments
(closed)
Web developers are quite annoyed that position: fixed doesn’t work on mobile browsers, but mobile browser vendors cannot afford to support it. This dilemma is unsolvable by the means we presently have at our disposal.
To offer a way out, I’m proposing to create a new position: device-fixed declaration better suited to the mobile scenario with its tiny screen and its zoom. The zoom aspect, in particular, is completely ignored by the spec, and so far mobile browsers haven’t found a good solution, either.
With a new value, fixed positioning could be split into a desktop and a mobile variant, and browsers could decide which one to support. That would allow web developers to devise separate solutions for desktop and mobile.
1 October 2010
Permalink
| in Touch events
7 comments
(closed)
Last Tuesday I blogged about event delegation on the iPhone and concluded that the click event, contrary to all others, is not delegated upward unless you also give the element the user clicks on an onclick event handler (which may be empty).
Turns out this is not the whole story.
28 September 2010
Permalink
| in Touch events
11 comments
(closed)
From the dawn of history browsers have supported event delegation. If you click on an element, the event will bubble all the way up to the document in search of event handlers to execute.
It turns out that Safari on the iPhone does not support event delegation for click events, unless the click takes place on a link or input. That’s an annoying bug, but fortunately there’s a workaround available.
15 September 2010
As we all know, media queries are by far the best way to distinguish between desktop and mobile browsers, or, more generically, between the dozens of different screen sizes our users can have. Media queries are the future of the web.
Nonetheless, the fact that they are the future doesn’t mean that there are no problems. One is particularly tricky: what do we do for browsers that don’t support them?
14 September 2010
If you want to make your websites ready form mobile, it’s best to combine <meta name="viewport" content="width=device-width"> with width media queries. That will give your site the optimal width (as determined by the device vendor, who really ought to know), and your site will look the better for it.
Lanyrd, Simon and Natalie’s latest brainchild, uses exactly this technique, and it establishes the perfect mobile browsing baseline. Try it on as many mobile browsers as you can, and you’ll see. No frills, just a simple user experience that just works.
In order to understand why we should use exactly this combination we should briefly repeat what meta viewports and media queries are all about.
On Tuesday Jason Grigsby challenged the conventional view that media queries are all we need to make a website mobile-friendly. Although he’s right when he points out some serious problems, I do not think that media queries are the “fool’s gold,” as Jason says. The message seems to be more that media queries alone are not enough to make your sites mobile-friendly. An additional component is required.
About a month ago I release part one of my series “A tale of two viewports,” where I discuss the widths and heights of the viewport, the <html> element, and related issues on desktop browsers. Today I release part two, which deals with the mobile browsers. And of course there’s the inevitable compatibility table.
Back in November I started complicated research into measuring the widths and heights of various interesting elements in mobile browsers. This research kept me occupied for months and months; and frankly I became a bit afraid of it because the subject is so complicated.
Besides, when I re-did some tests in March I pretty quickly figured out I’d made some nasty mistakes in my original tests. Back to the drawing board.
However, after a review round by some browser vendors and some rewriting it’s done now.
Today I present
A tale of two viewports — part one.
I explain CSS vs. device pixels, the viewport, several interesting JavaScript properties,
and the media queries width and device-width.
This piece is about the desktop browsers, because the mobile story is much easier to follow if you know exactly what happens on desktop. Later on I’ll publish part two, which is exclusively about mobile.
For my DIBI presentation I need a dropdown menu (in order to compare it on desktop and mobile), so I wrote one.
Point is, it took me thirty lines of JavaScript, nine of which only contain a closing },
and three of which deal with the fact that bloody Firefox still doesn’t support contains().
Net amount of lines: 18. Can somebody please remind me why we all used to think dropdowns are so extremely complicated? I can’t for the life of me figure it out.
Right now Jason Grigsby’s excellent summary of the orientation media query is making the round of blogs and tweets, and that’s well deserved. Media queries will become extremely important in the near future, when we have to build websites that work on any device resolution from 300px to 1280px or more.
Still, there’s one tiny nitpick I’d like to make, so that you fully understand when to use orientation and when to use device-width.
One reaction I received about my touch research was: Do we really need the touch events? Can’t we just fire the mouse events when a touch action occurs? After all, touch and mouse events aren’t that different.
That’s a fair question. It deserves a fair answer.
It turns out to be possible to handle the touchmove and touchend events with data obtained from the touchstart event object. It is not necessary to access the touchmove and touchend event objects, as long as you continue to have access to the touchstart one.
Apparently, the touchstart event object persists in browser memory even when the event has long ended. More importantly, it continues to be updated with information about the current touch action.
This is interesting. It’s also profoundly different from the desktop, where a similar trick with the mousedown, mousemove, and mouseup events definitely does not work.
Both iPhone and Android display this behaviour. Therefore future implementations of the
touch events should, too.
Update: I’ve been given to understand that this behaviour will disappear from WebKit. So don’t build your scripts with this behaviour; they’ll misfire sooner or later.
Over the past few weeks I have done some fundamental research into the touch action and its consequences, and it’s time to present my conclusions in the form of the inevitable compatibility table. I have also written an advisory paper that details what browser vendors must do in order to get by in the mobile touchscreen space. Finally, I discuss a few aspects of my research in this article.
Disclosure: This research was ordered and paid for by Vodafone. Nokia, Microsoft, Palm, and RIM have helped it along by donating devices to me.
When a user touches the screen of a touchscreen phone, sufficient events should fire so that web developers know what’s going on and can decide what actions to take. Unfortunately most mobile browsers, especially Opera and Firefox, are severely deficient here.
The touch action is way overloaded, and most browsers have trouble distinguishing between a click action and a scroll action. Properly making this distinction is the only way of creating a truly captivating mobile touchscreen browsing experience.
The iPhone’s touch event model is excellent and should be copied by all
other browsers. In fact, these events are so important that I feel that any browser that does
not support them by the end of 2010 is out of the mobile browser arms race. There’s only
one problem with the iPhone model, and it’s relatively easy to fix.
I have created a drag-and-drop script that works on iPhone and Android
as well as the desktop browsers,
a multitouch drag-and-drop script that works only on
the iPhone, and a scrolling layer script that
forms the basis of faking position: fixed on iPhone and Android, who do not
support that declaration natively.
I will hold a presentation on my research at the DIBI conference, Newcastle upon Tyne, 28th April. It will likely include future discoveries and thoughts.
1 August 2008
Permalink
| in Apple, Coding techniques, Content, Touch events
14 comments
(closed)
Yesterday I walked into the local phone store because the “Temporarily Unavailable” sign had been removed from their “Get your iPhone here” poster. To my utter surprise they had six (6!) entire iPhones for sale, and no, there was no waiting list. I walked back home with a shiny new gadget, impatient to start testing it.
Meanwhile I’ve done some tests; now it’s time for a report.
Before we continue, let’s get the bad CSS news out of the way: Safari on the iPhone does not support position: fixed. Certain Other Browsers were ridiculed for this lack; Safari won’t be.
I’ve updated the CSS Table, the Core Table and the Events Table. In this entry I’m going to talk about JavaScript events on the iPhone. They’re — interesting.
14 April 2008
Permalink
| in Coding techniques
10 comments
(closed)
Nowadays many JavaScripters are aware of the advantages of event delegation. Chris Heilmann and Dan Webb, among others, have discussed its advantages, and I've been using it as much as possible for about two years now.
Event delegation is especially useful in effects like dropdown menus, where lots of events on links may take place that can easily be handled at the root level (an <ol> or <ul> in this case).
There used to be one problem, though: although event delegation works fine for the mouse events, it does not work for the focus and blur events we need to make dropdown menus keyboard-accessible.
In the course of my ongoing event research, however, I found a way to delegate the focus and blur events, too. Maybe one of those frightfully clever JavaScript library authors will use this technique to shave off a few milliseconds of computing time
For all I know they're already aware of this technique; but it was new to me so I publish it anyway.
14 January 2008
Permalink
| in Coding techniques
25 comments
(closed)
The previous version of the Find Position script didn't work quite correctly,
since it often ignored the last step in position calculations: the one from the <body>
to the <html> element. Part of the reason was that its code was too complicated.
The problems with this script used to generate a lot of comments. Eight months ago I changed the script somewhat, and comments dropped off to zero, meaning I'd done it right. Meanwhile I've taken another look at it and changed it a bit more.
In any case, the changed script now uses a new approach (that is, it was new to me eight months ago).
It now uses the assignment operator = instead of the equality operator ==
that you'd expect:
while (obj = obj.offsetParent)
I always planned to write a blog entry about this approach, because I feel this little trick should become general knowledge. So here it is (eight months too late, but anyway):
12 March 2007
Permalink
| in Coding techniques
22 comments
(closed)
While attending Brian Fling's presentation on desiging for a mobile phone, I suddenly had an idea that might solve one of the problems he mentioned. I thought I'd document it immediately, before tonight's beer will cloud my mind and make me forget all about it.
6 February 2007
Permalink
| in Content, Redesign, XMLHTTP
4 comments
(closed)
I added a new page about importing the site navigation on all QuirksMode.org pages. The page is mostly about why I do what I do, and less about the how (besides, technically it's quite easy). The site navigation is a perfect example of what Jeremy calls Hijax.
I also put my trusty XMLHttpRequest functions online for future reference. No explanations on this page; I already treated them in section 10A of the book.
Just now I delivered a project during the making of which I noted a feature of event bubbling that, though totally logical, came as a surprise to me. No doubt someone else will be surprised, too, and may even be able to use it in a project.
In the last days of last year, while I was enjoying a holiday from obtrusive RSS feeds, the JavaScript library discussion seems to have heated up once more. Here's an overview of recent thinking about JavaScript libraries. The remainder of this entry is going to concentrate on the Stuart's and Chris's articles, in that order.
I'm already regretting the publication of my Browser Detect 2.0. From one of the comments I learned that there's a new script making the rounds of blogs, a script that neatly highlights the dangers of using browser detects, but that's been received with glad cries by otherwise sensible sites.
Combine the release of this script with my release, and it might seem to the unaware web developer that browser detects are back in fashion. It's necessary to repeat why browser detects are dangerous, unprofessional and usually badly written, even though those facts have been general knowledge since at least 1998.
20 June 2006
Permalink
| in Coding techniques, Conferences, Theory
9 comments
(closed)
Well, I'm back from @media, and it was as wonderful as last year. I met lots of interesting people, talked about lots of geeky stuff, drank the amount of beer required by British law, and went on stage at a web conference for the first time—but I hope not for the last.
Well, my previous entry Is asynchronous communication really being used? has certainly elicited some interesting comments. The answer was a resounding "Yes"; and the replies allow me to take a first stab at defining a few Ajax use patterns.
9 June 2006
Yesterday I attended the 10th Sigchi.nl conference in Amsterdam, during which I had the pleasure of seeing Jared Spool, Jesse James Garrett, Bill Scott, Martijn van Welie, and Steven Pemberton in real live action. (Note to self: Jared and Steven are stiff competitors of Joe when it comes to being The Funniest Man at Web Conferences).
I'm not going to describe the conference in detail. Instead, I'd like to discuss an asynchronous communication question that popped into my head during Jesse James' presentation.
27 April 2006
Permalink
| in Coding techniques, IE
13 comments
(closed)
In a project I'm currently working on I encountered an Explorer bug that depends on the window you open a page with.
I post it here because I know that MSIE team members occasionally read my blog, and I have the faint hope that can they solve this bug, especially since it's messing up one of my projects (and, after all, what in the world is more important than my projects going smoothly <grin>, particularly when I have another important and exciting project that should be finished quickly but is held up by this bug).
27 January 2006
Permalink
| in Coding techniques, Mozilla
13 comments
(closed)
One of my minor irritations with Mozilla is that it doesn't support a few DOM methods and properties that, though not officially a part of the spec, are nonetheless extremely useful and supported by all other browsers. I'm especially thinking of the contains() method and the children[] nodeList. While going through the more abstruse parts of the Level 3 Core spec today I found a way to add contains() to Mozilla.
26 January 2006
Permalink
| in Coding techniques, Professionalism
26 comments
(closed)
Quite recently Google published the results of its Web Authoring Statistics research, in which about a billion HTML documents were parsed for popular class names, used elements and attributes, use of JavaScript and so on.
Sounds fascinating? You bet. There's just one slight problem: the actual data is totally inaccessible.
My last entry The AJAX response generated a few interesting comments, as well as a thoroughly non-scientific and non-representative poll on the use of the various output formats.
I asked which output format people used. Only a minority of the commenters indicated a clear preference, and their "votes" break down as follows: XML 5 votes, JSON 5 votes, HTML snippets 2 votes, plain text 2 votes, and pure JavaScript 1 vote. So it's clear that XML and JSON are currently the most popular output formats. I'd expected JSON to end slightly below XML, but I was wrong.
In the rest of this article I'd like to reply to some points that were made: the name "AJAX", rendering speed, error handling, the "evilness" of eval() and innerHTML and some other remarks.
Since my last AJAX project I've increasingly been wondering about the "ideal" output format for the AJAX response. Once you've succesfully fired an AJAX request, what sort of response should the server give? An XML document? An HTML snippet? A JSON string which is converted to a JavaScript object? Or something else? In this entry I'd like to discuss the three formats, with examples, and ask you which format you've used in your practical AJAX applications.
(This article has been translated into Spanish.)
6 December 2005
In the past two weeks I've again created an Ajax-driven interface, and as usual I discovered quite a few interesting XMLHTTP bugs and problems. This entry contains three Explorer and one Safari bug, and it talks about cloning nodes from HTML to XML, from XML to XML, appending HTML that contains a form, and extremely agressive caching.
In my ongoing quest for memory leaks I've come upon a mystery. A script that should leak memory according to the definitions and the experts, doesn't. Why not? I have no idea.
Since the comments to my previous posts contain a few useful links to memory leaks and closure resources, I thought I'd create a linkdump for future reference. Note that I only included those articles that explain what they're doing and why and give code examples. I ignored the pages that just throw scripts over the fence and leave it to the reader to figure out what they're all about.
20 October 2005
Permalink
| in Memory leaks
25 comments
(closed)
I made an obvious error in my previous round of experiments. We're going to start afresh.
20 October 2005
Permalink
| in Memory leaks
14 comments
(closed)
The plot thickens. I now have succesfully created a simple function that causes memory leaks. The problem is, I don't understand why.
Update: Incorrect experiments. This entry is closed.
19 October 2005
Permalink
| in Memory leaks
13 comments
(closed)
It becomes more and more apparent that creating the new addEvent() function is not for the fainthearted. I underestimated the many problems, and in the comments to my previous entry compelling arguments were raised against the winning code.
I've decided to take a few steps back and study the problem before messing about with the solution. I want to write a script that leaks memory. I'd like to judge how bad it is in practice and I'd like to see some practical code examples. Unfortunately I just can't get any function to leak memory. I'm afraid I just don't get it.
Well, that wasn't what anyone would call fast. Scott, Dean and I all had trouble making time to judge the contest. Besides, the quality of most of the entries was less and their length far greater than we'd expected. We had to wade through dozens of lines of script that didn't really make much sense to us, and that weren't really necessary to perform the job at hand.
Despite this disappointment we have determined a winner.
...<drumroll />...
I know, I know. I'm terribly late, not to say distinctly overdue, in judging the addEvent() recoding contest. The main reasons are that my clients now actively gang up on me to prevent me working on anything but their projects, and that the bit of spare time I've managed to squeeze from them is almost entirely taken by a very exciting new project that I hope to unveil within the next few weeks.
That said, today I finally found the time for the first round. I took a quick look at all the entries and judged them on formal grounds.
26 September 2005
On Thursday my Windows XP computer died. This was not entirely unforeseen, since it had taken to crashing at random instances, and also when I wanted to restart it after a night of inactivity. But now it didn't want to start up at all, and reinstalling Windows XP brought on yet another crash. Time for a new computer.
This thrilling episode of "My glorious life as a web developer" has played havoc on my schedule, which was rather tight to begin with. The main victim turns out to be the addEvent() recoding contest.
21 September 2005
readyState and the eventsAs we all know an xmlhttp script requires the use of the readystatechange event. In theory, using the load event is also possible, but Explorer doesn't support it on xmlhttp requests.
Both these events, and the readyState property, have a few odd quirks when used in an xmlhttp environment, though. These quirks don't impact standard xmlhttp scripts too much, but as soon as you want to use the event objects or readyStates other than 4 you need to know about them.
Remember that the addEvent() recoding contest closes in three days. Thursday is your last chance to submit your script, since I'm going to close comments on my Friday morning and start working on the judging.
12 September 2005
In my continuing quest to understand XMLHTTP I gathered some very intriguing material that I'm quite sure will save somebody else's ass. Today I offer a closer look at the abort() method, as well as an as yet unexplained bug in Mozilla which causes the responseXML to go missing.
My recent entry addEvent() considered harmful generated many interesting comments and technical pointers. It's clear that the original addEvent() function doesn't quite cut the cake any more, and it's equally clear that we badly need a function such as this to keep our scripts simple.
Hence I'd like to take the opportunity to launch an addEvent() recoding contest. Write your own version of addEvent() and removeEvent(), submit it by adding a comment to this page, and win JavaScript fame.
6 September 2005
Permalink
| in Coding techniques, IE
21 comments
(closed)
In a recent article on the IE Blog, Justin Rodgers talks about further CSS improvements in the ever more impatiently awaited IE 7 beta 2. His message is that CSS hacks will start to break in IE 7, and I fully agree.
Nearly two years ago I warned against the excessive use of CSS hacks, because I envisioned a situation like this. Web developers who rely on CSS hacks are going to have serious problems.
Currently I'm working on debugging a very complicated script that's supposed to xmlhttprequest a few pages to be shown in a "Dashboard". I already wrote about another aspect of the project in my previous entry, but now that I'm concentrating on the XMLHTTP aspects of this project I found out a few very interesting things about responseXML, as well as a complicated Explorer bug.
This entry treats these two points, since they should be documented.
Back in 2001 Scott Andrew LePera published the cross browser event handler script addEvent(), which was subsequently copied, revised, and used in many, many websites. I never used it, because I felt — and feel — it is wrong to assume that the W3C addEventListener and the Microsoft attachEvent methods are the same. They aren't, and the slight but important difference can trip up the unwary web developer.
Today I found excellent evidence that addEvent() can be harmful if it's used without intimate knowledge of the differences between the W3C and Microsoft event registration models.
When I first read Jesse James Garrett's article Ajax: A New Approach to Web Applications my reactions were "What a silly name", and "Not really new, is it?" Although both points of critique have been repeatedly and heatedly mentioned in the ensuing discussion, the concept seems to be taking the Web development community by storm. This can mean one of two things: either it's a promise or it's a hype. To decide the case, I offer an annotated link dump.
Since XMLHTTP is becoming more and more important I thought I'd create a linkdump, both for my own future reference and for other developers. Additions and comments will be gratefully accepted.
Quite by accident I found the article DHTML Leaks Like a Sieve by Joel Webber. It's an interesting read that I can recommend to all JavaScripters. Also, it may have disturbing implications for my current coding practices.
This is the blog of Peter-Paul Koch, web developer, consultant, and trainer.
You can also follow
him on Twitter or Mastodon.
Atom
RSS
If you like this blog, why not donate a little bit of money to help me pay my bills?
Categories:
{kind=link}